コラム
データサイエンス入門講座 第4回 抜け漏れ・異常値・表記の揺れにどう対処するか

数値化や再分類を阻む「データの汚れ」
前節では日付やフリーワード、「あまりに細かすぎる区分をするID」などは、数値化や再分類といった加工をすれば「活用のためのデータ」に採用できることを学びました。この作業を困難にし、活用の際に意図しない誤りを生み出すのが、「データの汚れ」です。データが抜けていたり、異常値が含まれていたり、表記が揺れていたりする場合に、問題が生じます。本節でこの問題について詳しくみていきましょう。
データの抜け漏れが生みだす問題と対処方法
第1回目の記事で、最終的な「活用のためのデータの条件⑤」として「中身のセルに抜け・漏れは基本的に許されない」ということを挙げました。データ分析でも、AIのアルゴリズムでも、基本的に1か所でもデータが空白となっていれば、その行は丸々使うことができません。データ分析やAI開発に使うツールによっては、こうした空白がデータに含まれているだけでエラーになって動かない、というものもあります。
そうでなくても分析や予測の精度が大きく低下してしまうことがあります。その理由は「1か所でもデータが空白となっていれば、その行は丸々使うことができない」という状況でエラーとならないように、ツール側で行われる対処法にあります。すなわち、「使えない行」があれば内部で削除してしまう、という処理によってエラーにならないようにしているからです。
元々のデータのサイズが大きく、たとえば100万人以上の顧客データがあるから、多少抜け漏れのある行を削除してもかまわないのではと考えられるかもしれませんが、怖いのは「1か所でも」という部分です。元のデータに利用可能な1000項目の情報が入っていたとして、そのうちわずか1%だけがまったくの偶然で「抜け漏れ」だったとしましょう。これらを使って100万人の顧客に対して1行ずつのデータを、抜け漏れに何も対処もせずに加工していった場合、「1か所も空白にならない」顧客は何人いるでしょうか?答えは100万人× 0.99の1000乗で43人だけ、ということになります。
せっかく顧客が100万人いて、1000項目もの利用可能な情報が含まれる素晴らしいビッグデータを持ちながら、知らず知らずのうちにツールの内部でそのほとんどが捨てられ、わずか43人だけの「たまたままったく抜け漏れのない顧客」だけが使われていることになってしまいます。これでは大した分析結果は得られませんし、AIの性能も出ません。このような問題に対してどう対処すればよいでしょうか?
活用のために数値化するのか、再分類するのかということにより、データの抜け漏れへの対処方法は異なってきますが、再分類の場合は比較的単純なやり方があります。それは「不明」とか「元データなし」といった形に分類するという方法です。
つまり、なぜか購買した商品IDが空白のままのデータとして存在していた場合、ふつうに商品大分類という形に再分類しようとエクセルを操作したり、プログラムを書いたりすると「どの商品大分類でもない」ということで最終的な「活用のためのデータ」においても空白、あるいは内部的に「エラー」という扱いのままのデータが含まれてしまう可能性があります。これをそのままにしてしまうと、前述のような問題にぶつかってしまうわけです。
このような場合、商品IDが空白なら明示的に「商品大分類が不明」というように分類するわけです。物ではなく何かのサービスを提供したなど、データの空白が生じる理由が何かしら、あるのかもしれませんが、少なくともいったんエラーにならないように処理すれば分析やAIでの利用は可能になります。
抜け漏れを含むデータを再分類する際にはこのような対処法が考えられます。数値化ではどうでしょうか?「抜け漏れ」という分類は考えられても、「抜け漏れ」という数値がいくつかはわかりませんのでそう単純にはいきません。統計学の専門用語ではこのような状況を「欠測データ」と呼んで、その対処法だけで1冊の本が作られるぐらいなので、興味がある方はそちらを参照してみるとよいでしょう。比較的初歩的な方法としては「エラーにならないように元データの時点で除外する」あるいは「何かそれらしい値を補完する」という考え方があり、後者は専門用語では単一補完法と呼ばれます。
このうちどちらを使ったらよいか、また「それらしい値」とは何かというのはケースバイケースです。購買した商品の金額が抜けているとは、無料のノベルティグッズの受取りなどで「0円」という取引の意味を示しているのだとしましょう。この場合「そういうへんな購買履歴はノーカウントにした方がいい」と考えるのであれば、集計の前に除外してしまうというのが前者の「除外」という処理です。あるいは、0という値を補完しても構いません。
基本的にこのような抜け漏れがほとんどないようであればどちらの処理をしてもそう結果に影響はしませんが、細かく言うと「購買商品の平均単価」という集計をする際などには、微妙な差異が生じます。すなわち、ノベルティグッズを除外した上で平均値を求めた方が、「0円」という扱いで平均値の計算に用いた場合よりも多少大きな値となるでしょう。極端なケースを挙げると、1度ノベルティグッズを受け取るついでに、1万円の商品を買った、という購買履歴だけが存在する顧客について、前者の処理をすれば「平均1万円」、後者の処理をすれば「平均5千円」ということになります。判断に困ったら、このような極端なケースを考えて、どちらがイメージに近いか考えてみてもよいでしょう。
また「0」という値での補完が問題という状況も実際には起こります。さすがに現在のスーパーマーケットのレジなどではほとんど発生しませんが、店員の不注意でお金は受け取っているものの、データとして入力を忘れている、という状況ではどうでしょうか?このような場合「0円」ということは基本的にないはずです。あるいはもっと現実的にこうしたデータの抜け漏れが起こりうる状況を挙げましょう。顧客に回答してもらったアンケートを分析しようとする場合に、年齢や予算といった数値情報について未回答、ということはしばしばあります。このような場合も「0才」「予算0円」と扱ってしまうのは不適切でしょう。
こうした場合、「それらしい値」として、抜け漏れのない他のデータの平均値を採用するという処理がしばしば行われます。たとえばスーパーマーケットの店員が入力し忘れた商品の金額として、1円といった値は非現実的ですし、100万円という金額も非現実的です。スーパーマーケットであれば1商品の単価は概ね百数十円程度から数百円程度のものではないか、というのが「それらしい」気もします。高級感を売りにしているのか、お買得感を売りにしているのかというお店の方向性でも変わってくるでしょう。そこで、抜け漏れのない他のデータから、「顧客が購買する商品の平均単価」を計算すればそれが「それらしい値」であると考えられるわけです。
顧客が年齢を記入していなかった場合も同様です。それが5歳児と考えたり、100歳のご長寿と考えたりするのも非現実的ですが、その中間の「それらしい値」として、いったん回答の得られた他のデータで平均年齢を計算し、それが40歳なら未回答者の値を「40」と補完する、というのが現実的な対処方法です。
もちろんデータの欠測についての本が書かれるぐらいなので、このような取り扱いの問題がないわけではありませんが、抜け漏れがごくわずか( たとえば1%未満)であれば、分析結果やAIの精度にそれほど大きな影響はありません。
また、何割ものデータが抜けている、という数値の項目が存在していた場合、そもそもこの項目自体を信用できないものとして、除外してしまうというのも一つの方法です。いっそ数値を敢えて「再分類」してしまうという考え方もあります。
たとえば何割もの回答者について年齢が未回答となっているのであれば、まず年齢を10代、20代、30代、…70代以上、年齢未回答といったように再分類してしまった方が、ムリに平均値を補完するよりよい結果が得られる、という考え方です。
また、ここで述べたことは「元々数値の入った項目」だけでなく、「生年月日から年齢を算出」といった日付型の数値化の際にも当てはまります。生年月日が空白になっていれば、そこから自動的に年齢を計算しようとしてもやはり空白やエラーになってしまうでしょう。このような場合も、平均年齢で補完したり、( 計算された)年齢を最終的なデータから削除したり、「年齢不明」というカテゴリーを含む再分類を行うことができます。
異常値による問題と対処方法
元データに抜け漏れが存在している場合だけでなく「あり得ない値が入ってしまっている」という状況も、データ活用の障害になることがあります。商品の金額として、操作ミスなどの事情で「999,999円」というデータが入力された場合どのようなことが起こるでしょうか?
こうした異常値も、人間が目視で確認するという作業をはさめば「業務のためのデータ」としてはそれほど問題にならないかもしれません。スーパーマーケットに約100万円の商品が存在することはほぼありえず、9という数字が並んでいればそれだけで目立ちます。したがって、日々の業務に携わる人たち同士では誤りは明らかで、その日のレジを〆る時に事情を話して帳簿には残らないようにすれば経営上問題はないかもしれません。しかし、「活用のためのデータ」にこうしたミスが少なからず含まれてしまうと話は変わってきます。
データ結合の時に述べたように、活用のためには何万行だとか時に何百万行ものデータを扱うことがあります。このとき、どこかの店舗で「この日入力ミスをしてしまった」という情報は、たいていの場合分析やAI開発をする人と共有されず、一行一行個別に目を通すこともできません。
そうすると、優良顧客の特徴を見つけるための分析や、優良顧客を識別するAIは、実は正しい「優良顧客」ではなく「入力ミスをされやすい顧客」を見てしまっていることになってしまうかもしれません。毎週約1万円ずつ購買してくれる顧客の1年間の購買金額は50万円ほどですが、そうした顧客が一度こうした入力ミスに遭遇しただけで、いきなり客単価が3倍に増えてしまうわけです。その結果、「入力の管理がいい加減な店舗の近くに住んでいる顧客は優良顧客になりやすい」といった分析結果やAIが得られてしまう危険性に注意する必要があります。
また数値だけでなく、日付からの数値化についても、こうした異常値の問題は起こり得ます。典型的な例としてはシステム内のテストデータとして「西暦0000年1月1日」という日付に生まれた、あるいはポイントカードを作ったという架空の顧客が、活用のためのデータに紛れ込んでくることがあります。私たちはこうした状況を指して「キリスト世代」と呼んでいます。
こうした異常な日付に対して何も対処せずに年齢や取引年数を算出すれば、当然「2千歳以上のご長寿」や「2千年以上取引のあるお得意様」といったあり得ないデータが得られてしまいますが、もちろんこれは適切ではありません。データの加工の際にはそれぞれの項目の最大値と最小値を確認して、異常な値が含まれていれば抜け漏れと同様に対処しましょう。つまり、排除するか、それらしい値で埋めるか、「不明」という分類にするか、ということです。
表記の揺れへの対処方法
データ結合の際にIDが適切に設定されていない例として「表記の揺れ」について述べました。氏名というフリーテキストの項目をキーとして使おうとすると、「渡辺か渡邊か」「姓と名とのスペースは半角か全角か」のような表記の違いにより、適切にデータを結合できません。このような表記の揺れは、数値化や再分類する場合にもやはり問題になります。
数値化の際に問題となる表記の揺れの典型例には「フリーテキストで書かれた日付」というものがあります。たとえば「業務のため」に人間が生年月日を読み取って、重要な顧客の誕生日を祝おうというだけなら、同じ日付に対して次表内のどのような表記を使っても問題はないかもしれません。
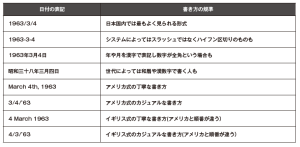
スラッシュで区切られていようが、ハイフンで区切られていようが、漢字を使っていようが、和暦であろうが構いませんし、外国人などであれば月を英語の略称で表現することも、日本人とは異なる順番で書く人もいます。いずれであっても人が見れば「あ、今日はこの顧客の誕生日だ」と判断することができます。その判断に自信がなくても「ひょっとして今日お誕生日ですか?」という会話が顧客との間で生まれることはそう悪いことではありません。
しかし、個別のデータを参照するのではなく、数万人以上の生年月日から年齢を計算しようとすれば、何らかのツールを使う必要が出てきます。こうした場合、いちいちデータの中身を確認し、どのような表記方法が使われているかの仕分けをしながら日付の形式をそろえて、そこから年齢計算をするプログラムを書かなければなりません。たいていの場合こうした作業は試行錯誤を伴い、見落としている例外的な状況のせいでエラーになっているところがないかを確認する必要があります。たとえば同じ英語圏でもアメリカ式とイギリス式で日付を書く順番が異なり、「25月12日」という不正な日付の値が現れることもあります。
日付だけではなく、住所などについても同じことがいえます。住所というフリーテキストから都道府県ごとに分類をしたい場合を考えてみましょう。すべてのデータが必ず都道府県から始まっていれば「住所の最初の2文字が何か」というだけで都道府県は特定できますが、必ずしもそうではありません。政令指定都市などの住所は都道府県を省略して書くことが多いですし、自宅近辺の店で住所を登録する際には「どうせ近所だから郵便物も届くだろう」と、市町村すら省略して住所を記入する人もいます。大阪市福島区の人が市を省略して書けば「住所の最初の2文字が何か」という判定では福島県民ということになってしまいます。こうした住所の表記についても、業務のデータという観点では「郵便物が届くから大丈夫」ということで問題になりませんが、活用のときにはエラーや抜け漏れのリスクが生じたり、それを回避するためのたいへんな手間がかかったりすることになります。
このような表記の揺れに対して、私たちはどう対処すればよいでしょうか?
正攻法としては、活用に耐えられるようにすべてのデータをきっちり構造化しておくべきです。都道府県という情報が必要なら、市区町村以下の住所をフリーテキストで記入し、都道府県については必須入力で選択させる、という形式にすればよいでしょう。また日付についても年、月、日、をそれぞれ別々に選択させたり、形式のチェックを厳密にしたり、といった対処をしておきます。それ以外の情報も、データとして分類できるように、数値として使いたいのであれば半角の数字だけで、といったように最初からデータ活用をしやすい形でデータを入力しておけば、いざ活用しようとする際に余計な手間がかかりません。
ただ、次のシステム改修を待たずにデータ活用を進める必要がある場合は、そうした正攻法は難しいかもしれません。現実的にどう進めていくべきでしょうか?
こうした場合、ある種の割り切りが役に立ちます。データの形式をそろえることや、正確な数値化や分類に労力がかかりすぎるようであれば、8~9割程度の数値化や分類が終わった状態で、それ以外を抜け漏れと同じように対処してもよいでしょう。もちろんこうした項目を丸々「いったん後回しにする」という判断をしても構いません。
これは抜け漏れや、異常値についても同様のことが言えます。データをキレイにすることはあくまで活用のための手段です。ある程度の割り切った判断をしながら「ひとまず今あるデータを使って、できる範囲で分析やAI開発を進めてみる」ことがおすすめです。
次節は締めくくりとして、現実的なデータ活用のプロセスのために、どのような姿勢でデータ整備を進めていけばよいかを説明しましょう。
データ分析や活用、DX推進に関するお悩み、弊社製品の機能についてご興味のある方は、お気軽にお問い合わせください。