コラム
データサイエンティストが不要になる?「拡張アナリティクス」の衝撃

「拡張アナリティクス」という言葉を耳にすることが増えてきました。ガートナー ジャパン株式会社 (以下 ガートナー) は、今年の6月10~12日に開催した「ガートナー データ&アナリティクス サミット 2019」(出典:ガートナー データ&アナリティクス サミット 2019 https://gartner-em.jp/data/)において、2019年のデータ/アナリティクス・テクノロジ・トレンドのトップ10について言及しました。それらのうち最初に彼らが言及したのが「拡張アナリティクス」という聞き慣れない言葉です。ではこの拡張アナリティクスとは一体何なのでしょうか?
目次
データの収集・加工作業が
多くのデータサイエンティストの時間を奪っている
ガートナーの説明はこうです。
”拡張アナリティクスがデータ準備、洞察の生成、洞察の可視化を自動化することによって、多くの状況においてデータ・サイエンティストの関与が不要になります”
※出典:Gartner, Press Release, 2019年5月30日「ガートナー、2019年のデータ/アナリティクス・テクノロジ・トレンドの トップ10を発表」https://www.gartner.com/jp/newsroom/press-releases/pr-20190530
ここに「データサイエンティストの関与」という言葉が登場しました。近年データサイエンティストという仕事に対する関心は高まっており、多くの会社で採用したり、育成しようという機運が生まれていますが、そもそもデータサイエンティストというのはどういう仕事をする職業なのでしょう?
こちらにちょうど米国のクラウドソーシング会社であるCrowdFlower Inc. (以下「CrowdFlower社」)がデータサイエンティストに対して「何に一番時間を使っていますか?」と調査を行った結果があるので紹介しましょう。
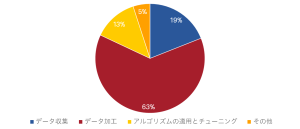
出典:https://visit.figure-eight.com/rs/416-ZBE-142/images/CrowdFlower_DataScienceReport_2016.pdf よりデータビークル作成
企業の内外で高度な数学や機械学習技術を習得し活用してきたデータサイエンティストですが、実は使う時間の多くはデータの収集または加工に費やされ、合わせて彼らの82%が、これらに一番時間を使っていると回答しています。逆に、分析や予測のために統計学や機械学習の手法を適用したり、その精度を向上させることに集中できていると答えられるデータサイエンティストはアメリカにおいても13%しかいないということがグラフから読み取れます。これは言わば、スカウトしてきたメジャーリーガーにグラウンド整備とグローブ磨きをさせている状態です。もしそうだとしたら、実にもったいない話ですね。こうしたもったいなさを解決するのが拡張アナリティクスなんです。
一般のビジネスパーソンでも
正確な予測値を算出できるようになる
さて、こうした問題意識がまさに弊社創業の直接的な理由の一つでもあります。
弊社共同創業者の西内啓(代表取締役最高製品責任者)は創業前、数年間にわたり多くの企業のデータ分析を支援してきたところ、三つの点に気づきました。
1)ビジネスシーンの分析において最も手間がかるのはデータ加工である
2)次に手間がかかるのがどのような変数・特徴量を用いるかの試行錯誤である
3)この二つの専門性の高い作業を自動化できるだけのノウハウが既に自分にはある
そしてさらに、もしその自動化が適切であればデータサイエンス人材の生産性は劇的に向上するし、一般のビジネスパーソンであったとしても、データから業務を改善するアイディアを得たり、正確な予測値を算出することができるのではないかと考えたわけです。
これがデータベースから生データを抜き出し業務課題を入力するだけで分析用データセットを自動的に生成し、説明変数をわずか数十秒で自動的に取捨選択、その読み取り方を自然言語で説明したりグラフ化してくれる、という弊社の製品dataDiverが生み出された背景にあります。
呼び名のないジャンルにつけられた
「拡張アナリティクス」という名前
ここでひとつのエピソードを紹介します。データビークルが創業されて間もない2014年の冬、大阪ガス株式会社ビジネスアナリシスセンター所長の河本薫氏(肩書は当時。現滋賀大学データサイエンス学部教授)に初期バージョンの製品をご覧いただいたところ、「私のところには世界中から分析ツールの紹介が来るが、未だかつてこれと似た製品を見たことがない」と言われました。
BIツールでもなく、SASやSPSSのような統計解析ツールでもなく、「これは一体何というジャンルのツールなのか?」と聞かれても当時の私たちは答えられなかったわけですが、それもそのはずです。それから5年後にやっと「拡張アナリティクス」という言葉が生まれたのですから。
ところで、いまだに「拡張アナリティクス」という製品カテゴリーは新しい考え方であり、データベース市場やBIツール市場といったような、「拡張アナリティクス市場」という確固たる括りが現時点ではありません。
しかし、例えばミック経済研究所は比較的似た概念として、「AI構築自動化ソリューション」というカテゴリーで市場動向を整理しています。例えばこの中にはDataRobot, Inc. (以下 DataRobot社)のDataRobotに代表される、機械学習アルゴリズムの構築に特化した製品も含まれますが、このカテゴリーにおいておかげさまで弊社は既に国産クラウドサービスベンダーとしてトップシェアを得ております。
データサイエンティストがより高度な
課題に集中できるような世界を目指して
なお、拡張アナリティクスによって「データサイエンティストが不要になる」のではなく「多くの状況でデータサイエンティストが不要になる」という表現をガートナーがしている点は気をつけておくべきポイントです。
実のところ、新商品のアイディアを考えたいとか、新しいマーケティングプランを考えたいといった多くのデータ分析の場においては、それほど高度なデータの加工や分析手法が求められるわけではありません。そこは拡張アナリティクスツールにより自動化した方が効率的という意味であり、高度な課題には相変わらず優秀なデータサイエンティストが必要になることにこれからも変わりはないでしょう。そうやって生み出された時間の余裕によって、データサイエンティストにはより重要で、高度な課題に集中できるような世界になることが理想である、というのが私たちの願うところでもあります。
データの準備、わかりやすく正確な分析結果の考察、高度な機械学習技術を応用した高精度な予測値の算出などなど、お客様の実データと問題意識に支えられて、弊社の拡張アナリティクスツールdataDiverはとにかく便利で生産的にデータサイエンスの技術を活用できるようアップデートを進めてまいりました。
本稿を読まれたみなさまも、もし今後「データサイエンスの人手が足りない」という悩みや、「もっと拡張アナリティクスについて知りたい」というご要望があれば是非、弊社までお問い合わせ下さい。
データ分析や活用、DX推進に関するお悩み、弊社製品の機能についてご興味のある方は、お気軽にお問い合わせください。