コラム
データサイエンス入門講座 第19回 ズルのできない予測精度の検証方法(2)

過学習を見抜くためのフェアな評価方法
過学習がなぜ問題になるかというと、今あるデータに対してもっとも予測値と実際の値のズレが小さくなるように計算した状態で、その計算に使ったデータにおける「予測値と実際の値のズレ」を評価しようとしていたからでした。本当に知りたいことは「いまあるデータにおけるズレ」ではなく、新たに開発された商品のように「次に得られるデータ」において、できるだけ正確に予測できる状態であるはずです。このギャップが、過学習の生じている予測モデルやAIにおいて「実際に使い始めたときに思ったような精度でない」という残念な結果の背後にあります。
そのため、「過学習」を検証するには、とりあえず実際に動かし始めて、ある程度何度か「新しいデータを予測して実際の値とのズレを確認してみる」というのも1つの方法です。しかしその時点で、予測精度が不十分だったことに気づいてまた改めて開発をやり直すのでは時間がかかってしまいます。
そこで行うのがクロスバリデーション(交差検証)法と呼ばれる評価方法です。クロスバリデーション法は今扱えるデータを、予測モデル(あるいはAI)を作る「トレーニングデータ」と、その精度を検証するためのテストデータに分けて、「新しくデータが来た時にどの程度の性能になるか」を検証します。予測モデルを訓練するから「トレーニング」、その精度を試すから「テスト」というわけです。なお、基本的にはトレーニングデータの方がたくさん必要なので、今回の例のように使えるデータの件数が少ない場合には「1個だけがテストデータで残りすべてがトレーニングデータ」とするのが一般的です。
試しに、さきほどの4つの製品について直線的な関係を考える単回帰分析を行うとして、その予測精度をクロスバリデーション法で評価してみましょう。バイヤーからの評価の平均点が60〜80点の商品だけであてはまる直線を考えて、その精度を残った90点の商品で見ると次のようになります。
3つのトレーニングデータから得られた「もっとも当てはまりのよい直線」は y=10,000x-390,000というものだったので、このxの値に90という値を入れると51万個という予測値が得られ、実際の値は予測値よりも40,000個も少なくなっています。(図表3-6)
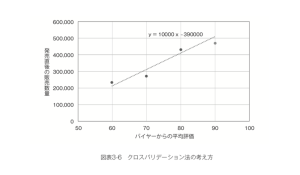
3つのトレーニングデータから得られた「もっとも当てはまりのよい直線」は y=10,000x-390,000というものだったので、このxの値に90という値を入れると51万個という予測値が得られ、実際の値は予測値よりも40,000個も少なくなっています。(図表3-6)
ただしクロスバリデーション法はこれで終わりではありません。この縦に点の商品で予測し、90点の商品で精度を検証する、という評価が「たまたまもっともうまくいったケース」だからかもしれないからです。
したがって、それ以外にも「80点の商品をテストデータにして残りをトレーニングデータにする場合」「70点の商品をテストデータにして残りをトレーニングデータにする場合」「60点の商品をテストデータにして残りをトレーニングデータにする場合」という、考えられる4つすべての状況について同様の評価を行って、その結果をまとめると次のようになります。(図表3-7)
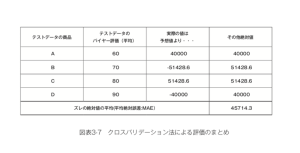
最初に見たバイヤーからの評価が60〜80点の商品をトレーニングデータとした予測モデルを、90点の商品をテストデータとした場合には、実際の値が予測値よりも40,000個も少ない、という結果でした。それ以外の組み合わせについても当然こうしたズレがあるわけですが、最終的にはこれらをまとめて「ズレの絶対値を平均したもの」である平均絶対誤差(MAE:MeanAbsoluteError)を用いて、よく予測モデルの性能は評価されます。今回でいえば、プラス側に外すにせよ、マイナス側に外すにせよ、平均すればこのようなバイヤーからの評価の平均値を使った直線的な販売数量の予測を今後用いた場合、「平均して4.6万個ほどは前後する可能性がある」と考えて運用しなければいけません。この水準が、現行の「勘と経験に基づく予測」と比べてどの程度、適切なものかも検討する必要があるでしょう。
なお、同様にトレーニングデータとテストデータを分けた場合、「トレーニングデータにおいて予測値と実際の値のズレが0になる曲線を当てはめる」という方針は、次に示すようにヒドい検証結果となることがすぐにわかります。(図表3-8)
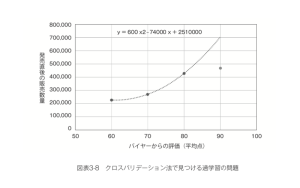
このように「1件のデータだけをテストデータとし、それ以外をトレーニングデータとして予測を行った結果どの程度ズレるかを計算する」ということを、すべてのデータが1度ずつテストデータとなるよう繰り返した上で、平均絶対誤差(MAE)などの形でまとめて評価する、というのがleave-one-outクロスバリデーション法です。leave-one-outとは「1つだけ外して」という意味です。
これ以外にも「全体の10分の1をテストデータとしてそれ以外をトレーニングデータに」というやり方で、やはりすべてのデータが1度ずつテストデータになるよう10回繰り返す場合は「10個に折りたたむ」という意味で10-foldクロスバリデーション法と呼ばれます。
また今回は、何個売れるかという数値を予測しようとしたため、平均絶対誤差などで「いくつ外しうるか」を考えましたが、「顧客が解約するかどうか」という状態についての予測モデルもありますし、省力化のためのAIの多くも「選ばれるか否か」という状態を予測します。このような場合はすべてのデータの中で、予測値と実測値がどの程度一致するかという的中率を用いて評価することになりますが、やはりクロスバリデーション法を使えば正確に評価できることに変わりはありません。
運用上注意すべき「どちらの外し方が怖いか」
このようにクロスバリデーション法を用いれば、社内や社外の技術者、あるいは自分自身で作った予測モデルやAIが、今後どの程度の精度で機能しうるかを正確に判断することができます。「データの得られた状態がこのまま続くとして」という仮定が成り立つ限り、基本的にはクロスバリデーション法から考えられる精度の範囲で予測は成立すると考えられるでしょう。
研究者ならば「これだけの精度で予測することができた」と論文に書けばよいですが、ビジネス上の判断としてはそうはいきません。ビジネスでは「平均的にいくつ外すか」「平均的にどれほど的中するか」という精度だけでなく、「どちら側に外す方が怖いか」という問題を考えなければならないからです。
先ほど商品の販売数量を予測すると、プラスマイナスそれぞれに4〜5万個ほど外す可能性がある、という検証結果が得られました。数学的にはプラス5万もマイナス5万も同じ絶対値ですが、ビジネス上これらは同じ意味を持つでしょうか?実際の値が予測値より5万個多い、というとき、その商品は倉庫に保管され、消費期限が切れる前に売り切るために、営業さんが走り回ったり、追加の販促費が必要になったりするかもしれません。一方で、実際の値が予測値より5万個少なければ、多くの店舗で品切れが続出し、問い合わせ対応に追われ、機会損失が悔やまれるかもしれません。
このどちらが怖いかは商品自体の消費期限や、取引先との関係、自社のブランドイメージによっても大きく左右されます。同じアパレル業界でも、流行の変化が速いレディースものであれば余らせることの方が怖いかもしれませんし、男性向けのビジネスウェアであれば次年度に売り切ることもできるためむしろ機会損失の方が怖いかもしれません。
したがって予測モデルが上がり、クロスバリデーション法による検証ができたら、その予測モデルに基づいて「怖い方」の可能性をある程度防ぐようにした場合、どの程度「怖い方」の問題が解決して、どの程度そのためのコストが許容されるかをシミュレーションしましょう。商品を余らせることが怖いのであれば「常に予測値より5万個少なめに生産する」という方針を取ればおおむねその心配は避けられます。一方でその商品については、最悪万個分の機会損失になるかもしれません。この分の需要を他の商品で代替できたり、品薄感がブランドイメージを向上させたりするのであれば、それも一つの戦略です。
一方で機会損失や欠品が怖いのであれば、常に予測値よりも5万個多く生産しておけばおおむねその心配は避けられます。場合により、最悪10万個ほど余らせてしまうことがあるかもしれませんが、その時点でいったん追加生産を止めて、いずれ売り切ることができるのであればそうした方法も合理的です。また、その中間あたりで「5万個多く生産して最悪10万個余るのは嫌だけど、3万個多く生産して8万個余る程度なら許容できる」という判断もあるかもしれません。
このように「この予測モデルでこれぐらいのバッファを持っていたら実際にどのようなことが起こり得るか」と考えるわけです。また、今回の例のデータでは極端に予測が外れるものはありませんが、プラス側にせよマイナス側にせよ「極端に外すケース」が、全データの中にどれぐらいの割合で含まれていて、その場合どの程度の経営上のデメリットがあるかを考えておきましょう。おそらく勘と経験で予測していた場合にも需要を読み誤るトラブルは何度もあったはずですが、そうした場合と比べて新たな予測モデルの性能は優れているといえるでしょうか?それとも「極端に外しそう」という部分だけは人間の勘で注意した方がよいでしょうか?
この「どちらに外す方が怖いか」という考えは、ある状態に該当するかしないかという目的変数を予測することが多いAIについても同様に応用することができます。「特定の病気かを診断するAI」というものがあったとして、精密検査に回すかどうかの判断で使うAIなら病気の人を見逃す方が問題になります。一方で、手術でメスを入れるかどうかという判断で使うような場合であれば、病気じゃない人を間違って病気だと誤診してしまう方が問題になります。誤って見逃す方が問題なのか、誤って混入させてしまう方が問題なのかというのは、同じ課題にフォーカスしていても、ユーザー層や使用目的によって、しばしば異なるわけです。このような場合についても、どちらの間違いを重視して、どのように運用した場合にどの程度「重視しない側の間違い」が起こりうるかシミュレーションしておくとよいでしょう。
以上のようなことが理解できれば、統計学を使っても機械学習を使っても、データに基づく予測や省力化を皆さんのビジネスの役に立てることができるはずです。
データ分析や活用、DX推進に関するお悩み、弊社製品の機能についてご興味のある方は、お気軽にお問い合わせください。